Soap Bubbles and Attention Sinks:
The Theory and History of the HALO-Loss

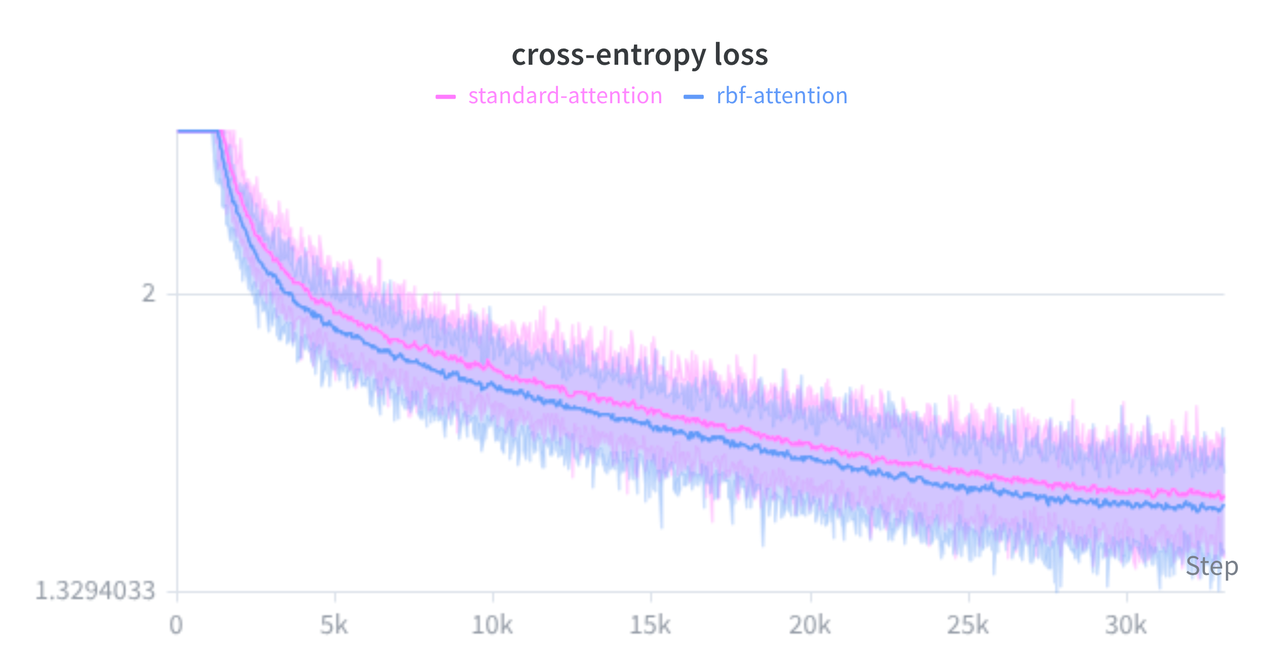
The standard Cross-Entropy loss has a well-known flaw: it forces neural networks to push their features toward infinity just to reach full confidence. The result is a messy latent space and models that confidently hallucinate when fed absolute garbage data.
This post breaks down my attempt to fix this with the HALO-Loss. It covers the weird geometry of high-dimensional "soap bubbles", how wiring a parameter-free "I don't know"-button directly into the classification head can significantly reduce out-of-distribution false positives, and a fast math trick to keep GPUs happy while doing so. HALO probably won't magically boost your raw accuracy benchmarks too much, but it can improve calibration and safety, mostly just by giving the network a mathematically sound place to throw its trash.